Temporal Difference Learning For Ultimate Tic Tac Toe
19 September 2019
This post accompanies the implementation of temporal difference learning that can be found on my github. This amazingly simple algorithm is able to learn entirely through self-play without any human knowledge, except for the rules of the game.
By way of example, we will be training the algorithm to play ultimate tic-tac-toe, but the same algorithm can be applied to almost any other game with varying degrees of success. This post will assume some familiarity with machine learning and reinforcement learning concepts, and should be accessible if you understand the basics of supervised learning with neural networks.
What is ultimate tic-tac-toe?
You probably already know how to play the original version of tic-tac-toe. Well ultimate tic-tac-toe is similar, except that each square on the board contains another, smaller game of tic-tac-toe! Let’s call the big game the “macro game” and the small games “micro games”. A player must win micro games to claim corresponding squares in the macro game. The goal is to win three micro games in a row. Simple, right?
Not so fast! There is a catch. The most important rule of ultimate tic-tac-toe is the following: The square you pick dictates the next micro game your opponent must play in. Specifically, whichever row and column you choose to play in a micro game is the row and column of the macro game your opponent is forced to play in next. So, for example, if you are first to move and you choose the middle square in any one of the micro games, your opponent must make their next move in the middle of the macro game. If this is confusing, take a look at Figure 1. Highlighted squares indicate where the current player is permitted to play.

Figure 1: A game of ultimate tic-tac-toe in progress. [source]
But what happens if your opponent sends you to a micro game that has already been won, or is full? Well then you are in luck! If this happens you are allowed to place your next move on any empty square on the entire board.
And that’s it! The game is won when three micro games are won in a row, either horizontally, vertically, or diagonally. The game ends in a draw if all micro games are over and no three in a row have been won by the same player.
What is temporal difference learning?
Temporal difference (TD) learning is a reinforcement learning algorithm trained only using self-play. The algorithm learns by bootstrapping from the current estimate of the value function, i.e. the value of a state is updated based on the current estimate of the value of future states. Read more…
Specifically, each time the algorithm is asked to make a move, the current model for evaluating the value of a state is applied to the states resulting from each currently legal move. The value of the current state is then updated using the rules
V(S_i) = V(S_i) + \alpha V(S_i+1)
where alpha is the learning rate.
The only time the current model is not used to determine state value is when the state is won by either player. In this case, the state is given the value -1 for a loss and +1 for a win.
Results
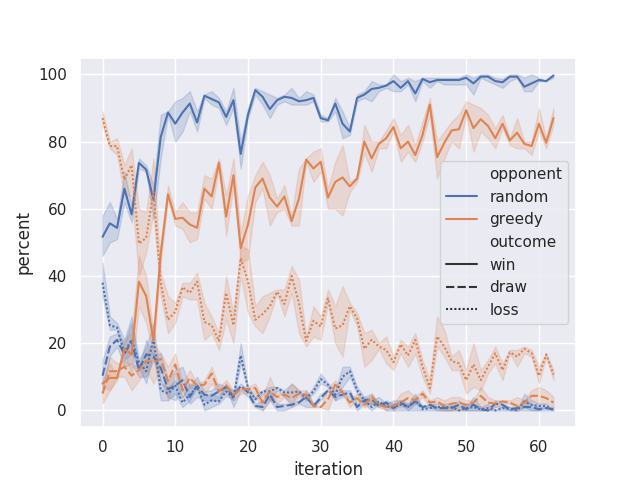
How to use
Training
To begin training:
python train.py
or set the learning hyperparameters using any of the optional arguments:
python train.py --lr LEARN_RATE --a ALPHA --e EPSILON
Playing
You can play against a trained model using
python player.py --params path/to/parameters.params
If no parameters are provided, the opponent will make moves randomly.
To-do
- Scale the value of terminal results by the game length to prefer shorter games.
- Implement UT3 neural network in other frameworks, eg: TensorFlow.
- Make asynchronous, i.e. do self-play, neural net training and model comparison in parallel.